准确的人类活动识别(HAR)是实现新兴的上下文感知应用程序的关键,这些应用程序需要了解和识别人类行为,例如监测独居的残疾人或老年人。传统上,HAR是通过环境传感器(例如,相机)或通过可穿戴设备(例如,具有惯性测量单元(IMU)的智能手表)来实现的。环境感测方法通常更适用于不同的环境,因为这不需要每个用户都有可穿戴设备。然而,在家庭等隐私敏感区域使用相机可能会捕捉到用户可能不愿意分享的多余环境信息。雷达已被提议作为粗粒度活动识别的替代模式,使用微多普勒频谱图捕捉环境信息的最小子集。然而,由于低成本毫米波雷达系统产生稀疏和不均匀的点云,训练细粒度、准确的活动分类器是一个挑战。在本文中,我们提出了RadHAR,这是一种使用稀疏和非均匀点云执行精确HAR的框架。RadHAR利用滑动时间窗口来累积毫米波雷达的点云,并生成体素化表示,作为分类器的输入。
我们在收集的具有5种不同活动的人类活动数据集上评估和演示了我们的系统。我们在数据集上比较了各种分类器的准确度,发现性能最好的深度学习分类器的准确率为90.47%。我们的评估显示了使用毫米波雷达进行精确HAR检测的有效性,并列举了该领域未来的研究方向。
毫米波(mmWave)技术在频率范围为30GHz和300GHz。由于,天线尺寸与频率成反比,频率越高在频谱中,天线的尺寸越小。因此,毫米波雷达在尺寸上是紧凑的。而且我们可以把大量的天线组装成一个非常小的实现高定向波束形成的空间(≈1◦角度精度)。由于这些雷达具有大的带宽,它们具有优越的距离分辨率。而且新的低成本,现成的雷达使其越来越受欢迎基于毫米波的传感解决方案。
在本文中,我们提出了RadHAR,这是一个利用生成的点云进行人类活动识别的框架。为了解决毫米波雷达点云稀疏性,RadHAR利用了这一概念人类活动通常持续几秒钟以上在一个滑动的时间窗口上积累点云。每个点云被体素化,然后被馈送到一组分类器中。我们在数据集上比较了各种分类器的准确度,发现性能最好的深度学习分类器的准确率为90.47%。
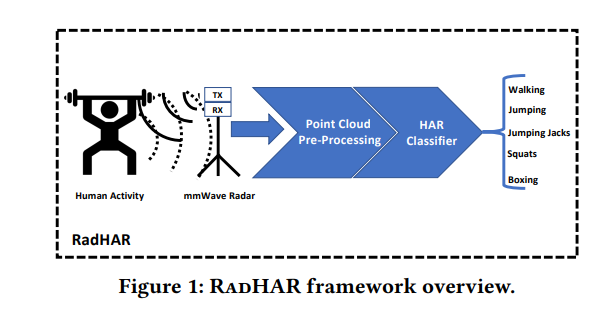
我们使用TI的IWR1443BOOST[8]雷达来收集新的点云数据集,称为MMActivity(毫米波活动)数据集。它是一种使用线性调频信号的FMCW(调频连续波)雷达。该雷达工作在76千兆赫到81千兆赫的频率范围内。该雷达包括四个接收器和三个发射器天线,可以通过距离和角度信息跟踪多个物体。
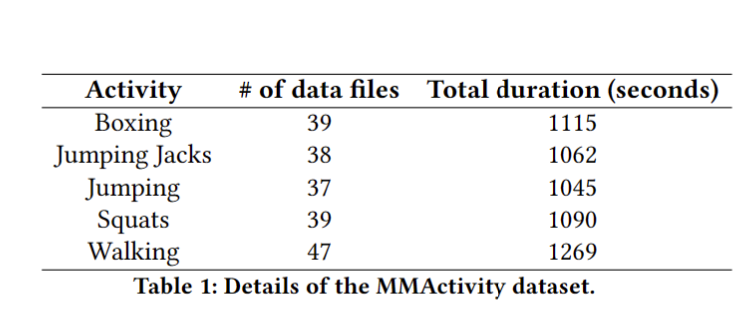
为了收集数据,雷达安装在1.3米高的三脚架上。用户在雷达前执行5种不同的活动,这些活动是:步行,跳跃,杰克跳跃,深蹲和拳击。对于进行相同活动的受试者,在约20秒的连续时间段内收集数据。有些数据文件的时间超过20秒。我们总共收集了93分钟的数据。数据集的描述可以在表1中找到。捕获的点云包含空间坐标(x,y,z,以米为单位),以及速度(以米/秒为单位)、距离(点与雷达的距离)(以米计)、强度(dB)和方位角(度)。雷达的采样率为每秒30帧。
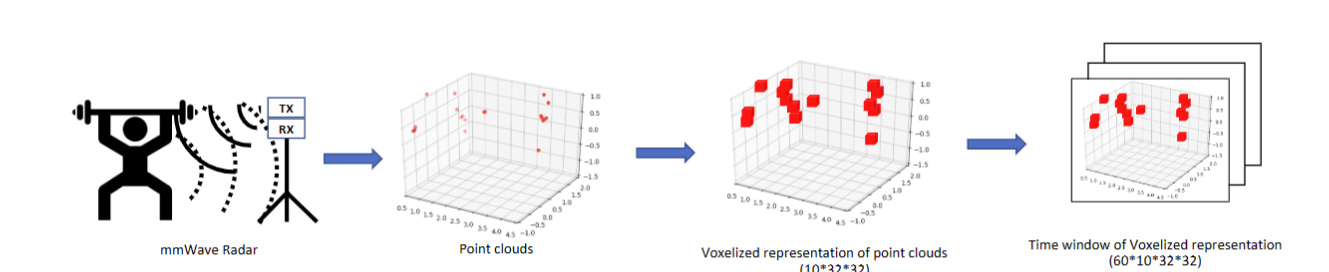
我们将收集的数据文件分为单独的训练和测试文件,其中训练中的数据为71.6分钟,测试中的数据是21.4分钟。为了克服每帧中点数量的不均匀性,我们将点云转换为尺寸为10x32x32(深度=10)的体素,这使得输入的大小不变,而与帧中的点数量无关。我们通过测试它们的性能,根据经验决定了这些维度。在我们的体素表示中,每个体素的值是其边界内存在的数据点的数量。虽然具有大量的体素可以很好地表示底层信息,但它将数据大小增加了几个数量级。
由于活动是在一段时间内执行的,因此会生成活动的时间窗口,以便捕获时间相关性。我们创建了2秒(60帧)的窗口,其滑动因子为0.33秒(10帧)。基于先前在多模式时间序列数据集[15]的人类活动识别和使用点云[18]的人类识别方面的工作,选择了2秒窗口。最后,我们得到了12097个训练样本和3538个测试样本。我们使用20%的训练样本进行验证。在时间窗口体素化表示中,每个样本的形状为601032*32。数据预处理过程如下:
我们在MMActivity数据集上评估不同的分类器。我们将支持向量机(SVM)、多层感知器(MLP)、长短期记忆(LSTM)和卷积神经网络(CNN)与LSTM相结合进行训练。我们比较了这些分类器在MMActivity数据集的同一训练和测试分割上的推理能力。这些深度学习分类器通常适用于广泛的应用。
SVM分类器,支持向量机(SVM)分类器的输入是通过将时间窗口体素化表示(60103232)平坦化,然后应用主成分分析(PCA)进行降维来生成的。我们使用主成分分析将数据的维度从614400(60103232)减少到6000。
3.4.2 MLP分类器。它由完全连接的层和输出层组成。我们将样本的时间窗体素表示(601032*32)压平,为MLP分类器创建614400维的输入大小。MLP分类器有4个完全连接的层,后面是输出层。我们使用丢弃层来避免过度拟合。它有3935万个可训练参数。
双向LSTM分类器。双向LSTM层由两个并行操作的LSTM层组成。第一层的输入按原样提供,而第二层的输入是数据的反向拷贝。因此,双向LSTM层保留了来自未来和过去的信息。该网络由双向LSTM层、2个完全连接层和一个输出层组成。网络的输入(6010240)是通过保留时间维度(60)并使样本(1032*32)中的空间维度变平来创建的。我们使用了大小分别为64和64个隐藏单元的双向LSTM。双向LSTM分类器具有529万个可训练参数。
时间分布CNN+双向LSTM分类器。时间分布的CNN将CNN层应用于输入数据的每个时间切片。时间分布CNN+双向LSTM分类器的结构由3个时间分布卷积模块(卷积层+卷积层+最大池化层)组成,然后是双向LSTM层和输出层。总体而言,该网络具有291k个可训练参数。该分类器直接在具有时间和空间维度的输入样本上进行训练。分类器精度如下


 /6
/6 



 工商网监
湘ICP备2023018690号
工商网监
湘ICP备2023018690号






 282
282



 淘帖
淘帖



