上期后续
在上一篇文章中笔者提到我的128G朗科内存卡坏了送去维保,同时三星的64G内存卡无法点亮飞腾派也是在今天顺利解决了这个问题
这里也是感谢相当负责任的飞腾社区负责人@alwinlee @kevin2011 同为本次试用名单的朋友给予的建议@tianyingkeji,来自本版块的负责人的点赞支持@dianzi @Jonny,以及来自上一批板厂论坛的测试者,你们的宝贵经验为整个飞腾派社群避免了诸多弯绕,再次感谢!!!
(↓↓↓上批测试者微信私聊答疑的截图)

(↓↓↓点赞诸位留言建议与鼓励的负责人)
总而言之,内存卡的容量与品牌选择需要着重注意一下,本次我重新购买的内存卡是来自 朗科的长江系列-32G ,倘如你遇到与我相同的问题(烧写镜像后无法点亮外围IO不通电),可以选择在京东上购买相同的型号
回归正文-测试飞腾派基础应用部署能力
工欲善其事,必先利其器:
笔者本次烧录的系统是PhytiumPIOS,更注重美观和开箱即用的可以尝试openkylin,但在飞腾派汇总的网盘资源中openkylin的镜像并非最新版本,在官网中可以找到最新的1.0.1版本,笔者所用如此( 请注意,对于开发工具而言并不能盲求最新,网盘总所整理的资源都是经过飞腾派社区测试通过的,如果在生产环境中部署,我仍然建议你从飞腾派网盘中获取镜像等资源 )
(openKylin官网下载)

选择并烧写好所需的镜像之后即可点亮开发板,在飞腾派这块板子上是没有GPU的因此在任何系统中都是mesa的llvmpipe也就是CPU渲染,因此系统的最高分辨率是1920x1080,也不建议各位手动添加更高的分辨率,这边笔者也是选择使用putty+winscp进行开发
让我们先来写一个PyQt的GUI简单例程:
首先咱们要先装个PyQt5的库。。。嗯?

很明显,在PhytiumPIOS的环境中,Python默认没有配置pip,这种事我相信大家应该很清楚如何解决,装一个嘛,我也就不过多解释,不知道怎么装的就把我下面给出的三行指令复制到终端就好
curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py

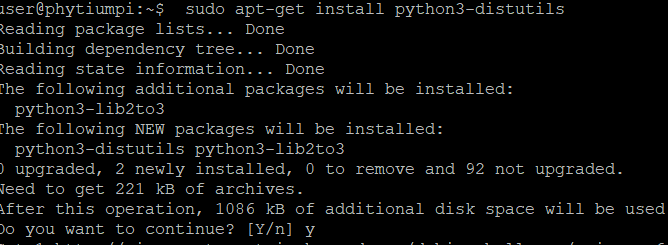
sudo apt-get install python3-distutils
python get-pip.py
如果你的系统是Ubuntu,那么恭喜你,系统中已经将Python的大多数环境配置完整了,并且QtBase环境也是如此只需要在系统中部署你开发好的应用就能直接上线
简单应用测试
既然环境已经有了,先来玩个游戏吧,比如说咱们打个飞机?
这是一个通过PyGame实现的外星人入侵的简单游戏,可以通过键盘来控制飞机的左右躲避,运行的效果还是相当可以的
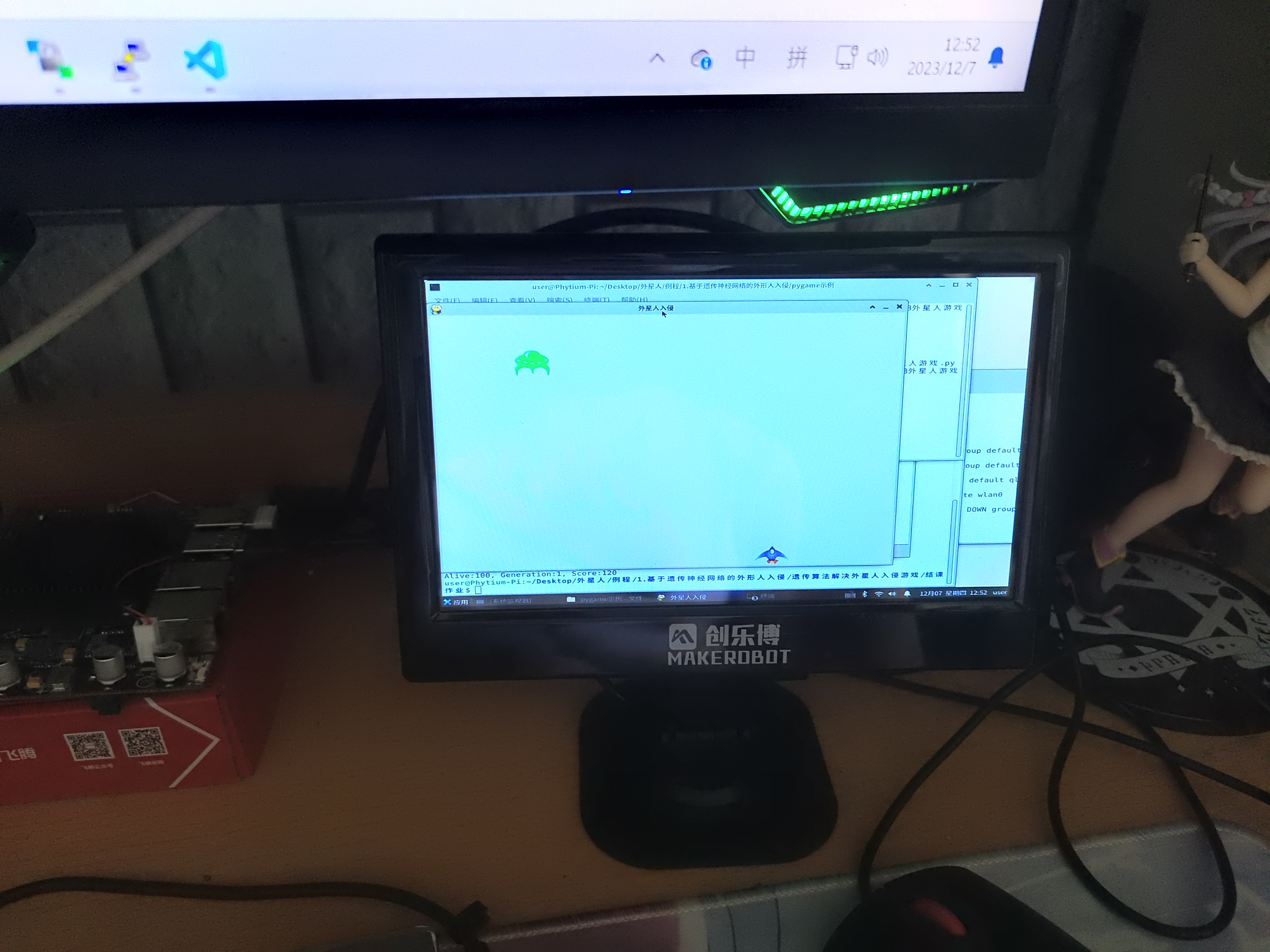
俗话说得好我都花钱买游戏了或者我都花时间做游戏了,我再花时间去玩游戏那我不是亏麻了?你已经是一个成熟的小游戏了该学会自己陪自己玩了,我不想动给它创建一个随机数让它自己动:
def think(self):
r = random.random()
if r < 0.20:
self.set_move_direction(1)
elif r < 0.40:
self.set_move_direction(-1)
else:
self.set_move_direction(0)
def move(self):
if self.move_direction == 0:
return
center = self.rect.centerx
if self.move_direction == 1:
center += self.ship_speed_factor
elif self.move_direction == -1:
center -= self.ship_speed_factor
self.rect.centerx = center
emmm,可是这样它一点都不成熟,动的太蠢了,一下子就死了,下饭菜也要有点油水是吧,给它增点智慧
先写一个简单的神经网络:
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(2, 64)
self.fc2 = nn.Linear(64, 3)
def forward(self, x):
x = torch.cat((x[:, 0].view(-1, 1), x[:, 1].view(-1, 1)), dim=1)
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
再改变一下它的思考模式:
def think(self):
with torch.no_grad():
enemy_tensor = torch.tensor(self.inputs[1]).float().view(1, -1)
plane_tensor = torch.tensor(self.inputs[0]).float().view(1, -1)
outputs = self.model(torch.cat((enemy_tensor, plane_tensor), 1))
_, predicted = torch.max(outputs, 1)
self.nn_out = predicted.item()
return predicted.item()
那么数据集应该怎么搞呢?既然要懒,那就懒到底,让程序自动生成一批:
def generate_data(data_size):
enemy_positions = np.random.rand(data_size)
plane_positions = np.random.rand(data_size)
labels = []
for i in range(data_size):
if abs(enemy_positions[i] - 0.2) <= plane_positions[i] <= abs(enemy_positions[i] + 0.2): #如果飞机在敌机撞击范围内
if 0.2 <= abs(enemy_positions[i] - 0.2) <= 0.8: #如果敌机在边缘范围之外
if abs(plane_positions[i] - (enemy_positions[i] - 0.2)) < abs(plane_positions[i] - (enemy_positions[i] + 0.2)): #如果飞机向左飞更快离开撞击区
labels.append(1) #向左飞行
else:
labels.append(2) #向右飞行
elif abs(enemy_positions[i] - 0.2) <= 0.2: #或者敌机在左侧边缘之内
labels.append(2) #向右飞行
elif abs(enemy_positions[i] + 0.2) >= 0.8:
labels.append(1) #向左飞行
else:
print(enemy_positions[i] , plane_positions[i])
labels.append(0) #原地不动
else:
if abs(plane_positions[i] - 0) < abs(plane_positions[i] - 1): #如果飞机坐标-0 小于飞机坐标-1
labels.append(2) #向右飞行
elif abs(plane_positions[i] - 0) > abs(plane_positions[i] - 1): #或者如果飞机坐标-0 大于飞机坐标-1
labels.append(1) #向左飞行
else:
labels.append(0) #原地不动
这下应该不蠢了吧,看看效果:

相当聪明啊,出道即巅峰
当然,咱们也不能纵情于娱不是?是时候来点工作了,来一套视觉检测的应用如何?
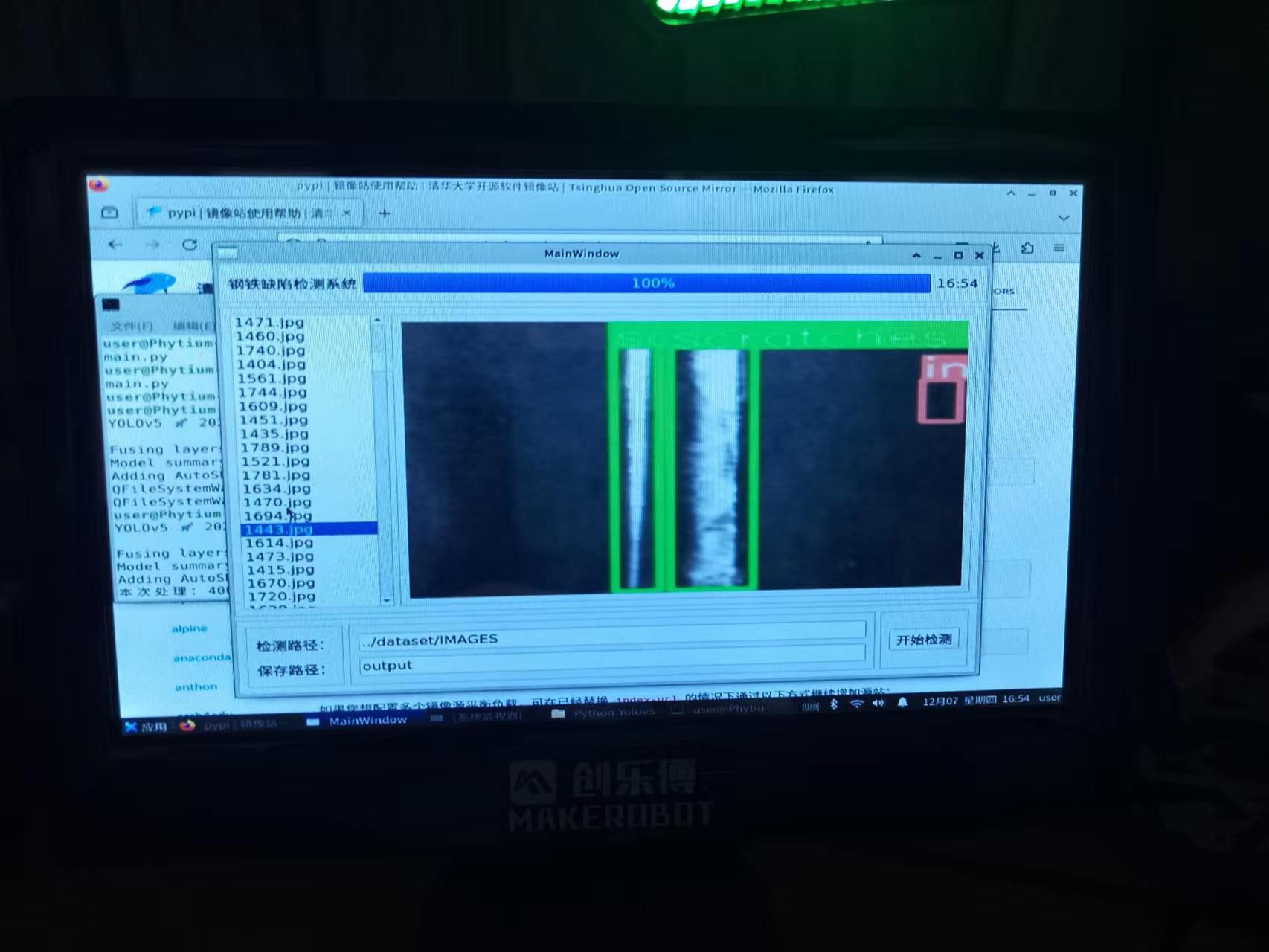
这是一个基于Yolov5 + PyQt实现的钢铁缺陷检测系统,实现也简单,拉取Yolov5的代码库,准备好数据集用Yolov5的训练脚本重新跑一遍,同时用QtC做一个UI再用Python实现基本逻辑调用训练好的模型即可
推理Demo:
import sys
from PyQt5.QtGui import QPixmap
from PyQt5.QtWidgets import QApplication, QMainWindow, QFileDialog
from PyQt5.QtCore import QTimer, QTime, Qt, QThread, pyqtSignal
from PyQt5.uic import loadUi
import os
import torch
import cv2 as cv
model = torch.hub.load('./', 'custom', path='best.pt', source='local')
class ImageProcessingThread(QThread):
update_progress = pyqtSignal(int)
update_list_widget = pyqtSignal(list)
def __init__(self, input_path, output_path):
super().__init__()
self.input_path = input_path
self.output_path = output_path
def run(self):
file_names = os.listdir(self.input_path)
total_files = len(file_names)
for i, file_name in enumerate(file_names):
img_path = os.path.join(self.input_path, file_name)
results = model(img_path)
frame = results.render()[0]
bgr = cv.cvtColor(frame, cv.COLOR_RGB2BGR)
save_file = os.path.join(self.output_path, file_name)
cv.imwrite(save_file, bgr)
progress = int((i + 1) / total_files * 100)
self.update_progress.emit(progress)
self.update_list_widget.emit(file_names)
class MyMainWindow(QMainWindow):
def __init__(self):
super().__init__()
loadUi("mainwindow.ui", self)
self.timer = QTimer(self)
self.timer.timeout.connect(self.update_time)
self.timer.start(1000)
self.Start.clicked.connect(self.start_processing)
self.listWidget.itemClicked.connect(self.show_selected_image)
def update_time(self):
current_time = QTime.currentTime()
time_string = current_time.toString("hh:mm")
self.Time.setText(time_string)
def start_processing(self):
input_path = self.InputPath.text()
output_path = self.OutputPath.text()
self.processing_thread = ImageProcessingThread(input_path, output_path)
self.processing_thread.update_progress.connect(self.update_progress_bar)
self.processing_thread.update_list_widget.connect(self.update_list_widget)
self.processing_thread.start()
self.Start.setEnabled(False)
def update_progress_bar(self, value):
self.progressBar.setValue(value)
if value == 100:
self.Start.setEnabled(True)
def update_list_widget(self, file_names):
self.listWidget.clear()
self.listWidget.addItems(file_names)
def show_selected_image(self, item):
selected_file = item.text()
selected_image_path = os.path.join(self.OutputPath.text(), selected_file)
pixmap = QPixmap(selected_image_path)
self.ViewImg.setPixmap(pixmap)
self.ViewImg.setScaledContents(True)
if __name__ == "__main__":
app = QApplication(sys.argv)
main_window = MyMainWindow()
main_window.show()
sys.exit(app.exec_())
那么推理速度如何呢?

可以看到,在不进行任何优化的情况下处理400张图片需要1180秒,平均每张图要3秒左右,这样的效率肯定是无法做到实时检测的,所以咱们还需要做一个最基本的处理-多进程优化
其实在我上面的代码中以及引入了一个QThread,这个是Qt所必须的多线程模块,否则在处理这种长时间的推理任务时会由于阻塞导致UI崩溃,这也是Python GIL需要处理的一个很复杂的内容
那么现在我所说的多进程优化是什么呢?其实就是针对单线程模型推理时有相当的系统资源其实是无法完全调用上的,这就会导致整体系统资源浪费和处理时间过长的问题,这样的程序对嵌入式设备来说是不合格的 (虽然也没人会在嵌入式设备中使用Python就是了)
我们从以下模块引入一些函数做后续调用
from concurrent.futures import ProcessPoolExecutor, wait
这是 Python 中用于支持并发编程的模块。它提供了高级的接口,使用这个模块可以使得我们在多线程(ThreadPoolExecutor)和多进程(ProcessPoolExecutor)环境中进行并发编程变得更加方便
用法如下:
with ProcessPoolExecutor() as executor:
futures = {file_name: executor.submit(process_image, self.input_path, self.output_path, file_name) for file_name in file_names}
done, not_done = wait(futures.values(), timeout=None)
for future in done:
file_name = [name for name, f in futures.items() if f == future][0]
future.result()
progress = int((len(done) / total_files) * 100)
self.update_progress.emit(progress)
这将创建多个图像处理进程,充分利用到系统中的现有资源(通常情况下该模块会自动根据CPU的线程数分配资源创建线程池),理论是如此,看看实际效果:

我们可以看到,在启用了多进程处理之后,整体耗时缩短了一半,虽然还是远不及实时监测的门槛(最起码每秒10张),但是最起码咱们能看到不充分的利用存在过半的资源浪费
倘若我们将该代码通过C++进行优化复现,那么实时监测并非难事
最后再来跑一个人脸识别的例程,在这个例程中还是使用的PyQt进行实现,那么为何要演示这个例程呢,主要是我认为对于编程,很多东西比起最优的模板实现,一些奇淫技巧是非常有意思的,我手上并没有可以接入飞腾派的图像采集设备,那么我是如何实现人脸识别的呢?

不知道有多少人用过上面这个APP,顾名思义这是一个将本地摄像头采集的数据以网络的形式在内网中转发

它可以相当方便的在我们缺少图像采集设备的时候临时顶用
实现效果:
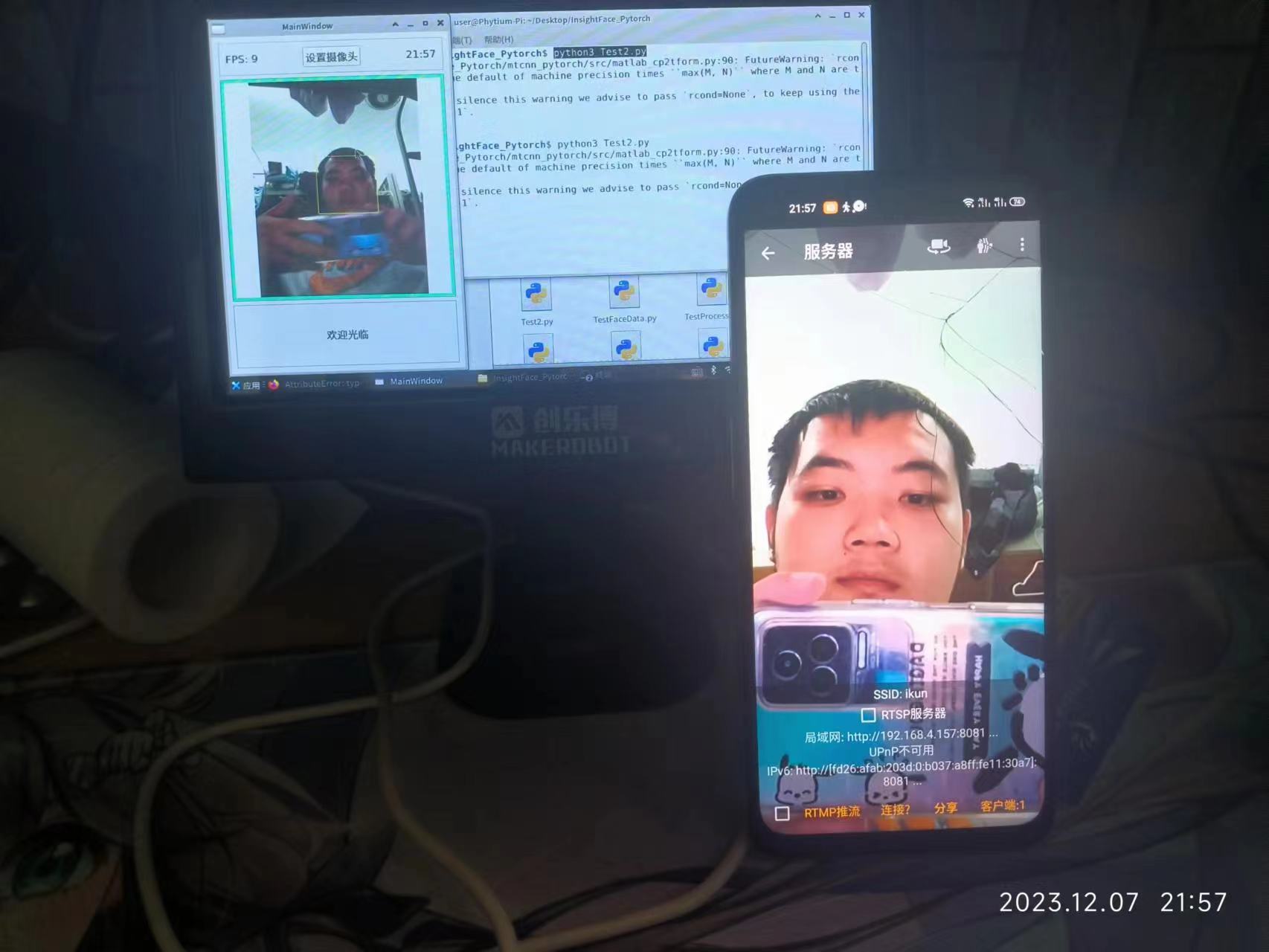
具体方案:
通过IP拉取视频流 -> opencv截取面部信息 -> MTCNN人脸相似度匹配
代码Demo:
import os
import sys
import cv2
from PyQt5.QtWidgets import QApplication, QMainWindow, QInputDialog
from mainwindow import Ui_MainWindow
from PyQt5.QtCore import QTime, QTimer, QThread, pyqtSignal, Qt
from PyQt5.QtGui import QImage, QPixmap
from PyQt5.uic import loadUi
from model import Backbone
import torch
from PIL import Image
from mtcnn import MTCNN
import matplotlib.pyplot as plt
from torchvision.transforms import Compose, ToTensor, Normalize
import numpy as np
import time
import threading
mtcnn = MTCNN()
device = 'cpu'
model = Backbone(num_layers=50, drop_ratio=0.6, mode='ir_se')
model.load_state_dict(torch.load('model_ir_se50.pth', map_location=torch.device(device)))
model.eval()
model.to(device)
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')
def get_img(img, device):
timestamp = str(int(time.time()))
output_dir = './log'
if not os.path.exists(output_dir):
os.makedirs(output_dir)
image_name = f'I1_{timestamp}.png' if type(img) == np.ndarray else f'I2_{timestamp}.png'
image_path = os.path.join(output_dir, image_name)
if type(img) == np.ndarray:
img = Image.fromarray(img.astype('uint8'))
elif type(img) == str:
img = Image.open(img)
img.save(image_path)
face = mtcnn.align(img)
transforms = Compose([ToTensor(), Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])
return transforms(face).to(device).unsqueeze(0)
def get_embeddings_from_image(img, model, device):
img = get_img(img, device)
return model(img)[0]
def load_folder_embeddings(folder_path, model, device):
embeddings = []
image_paths = []
for file in os.listdir(folder_path):
if file.endswith('.jpg') or file.endswith('.png'):
image_path = os.path.join(folder_path, file)
emb = get_embeddings_from_image(image_path, model, device)
embeddings.append(emb)
image_paths.append(image_path)
return embeddings, image_paths
def calculate_similarity(emb1, emb2):
return emb1.dot(emb2).item()
def find_matching_person(input_emb, folder_path, model, device, threshold=0.9):
folder_names = [name for name in os.listdir(folder_path) if os.path.isdir(os.path.join(folder_path, name))]
for name in folder_names:
embeddings, image_paths = load_folder_embeddings(os.path.join(folder_path, name), model, device)
for emb, path in zip(embeddings, image_paths):
similarity = calculate_similarity(input_emb, emb)
if similarity >= threshold:
return True, name
return True, "请联系管理员"
class ImageProcessingThread(QThread):
finished = pyqtSignal(list)
def __init__(self, img, model, device, threshold, folder_path):
super(ImageProcessingThread, self).__init__()
self.img = img
self.model = model
self.device = device
self.threshold = threshold
self.folder_path = folder_path
def run(self):
try:
input_emb = get_embeddings_from_image(self.img, self.model, self.device)
except Exception as e:
print(f"在 run 中出现错误: {e}")
signal = 1
result = "请联系管理员"
result = [signal, result]
self.finished.emit(result)
return
signal, result = find_matching_person(input_emb, self.folder_path, self.model, self.device, self.threshold)
result = [signal, result]
self.finished.emit(result)
class MainWindow(QMainWindow, Ui_MainWindow):
def __init__(self):
super(MainWindow, self).__init__()
self.setupUi(self)
self.Systimer = QTimer(self)
self.Systimer.timeout.connect(self.update_time)
self.Systimer.start(1000)
self.Setting.clicked.connect(self.showInputDialog)
self.show()
self.cap = None
self.face_image = None
self.is_processing = False
self.start_time = time.time()
self.frame_count = 0
def start_processing(self):
threshold = 0.75
folder_path = 'FaceData'
self.image_thread = ImageProcessingThread(self.face_image, model, device, threshold, folder_path)
self.image_thread.finished.connect(lambda result: self.set_UserName(result))
self.image_thread.start()
def set_UserName(self, result):
if result[0]:
Result = "欢迎:" + result[1] if result[1] != "请联系管理员" else result[1]
self.UserName.setText(Result)
self.face_image = None
self.is_processing = False
else:
self.UserName.setText(result[1])
def showInputDialog(self):
text, ok = QInputDialog.getText(self, '设置摄像头IP', '请输入IP摄像头的地址:')
if ok:
self.IP_Address = text
self.cap = cv2.VideoCapture(self.IP_Address)
self.timer = QTimer(self)
self.timer.timeout.connect(self.update_frame)
self.timer.start(50)
def update_time(self):
current_time = QTime.currentTime()
time_string = current_time.toString("hh:mm")
self.TimeLabel.setText(time_string)
def update_frame(self):
ret, frame = self.cap.read()
if ret:
self.VideoView.setStyleSheet("background-color: rgb(102, 204, 255)")
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
frame = cv2.rotate(frame, cv2.ROTATE_90_COUNTERCLOCKWISE)
gray = cv2.cvtColor(frame, cv2.COLOR_RGB2GRAY)
faces = face_cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=6, minSize=(200, 200))
if len(faces) > 0 and not self.is_processing:
self.VideoView.setStyleSheet("background-color: rgb(0, 255, 204)")
for (x, y, w, h) in faces:
cv2.rectangle(frame, (x, y), (x + w, y + h), (255, 255, 0), 2)
self.face_image = frame[y:y + h, x:x + w]
self.is_processing = True
self.start_processing()
elif len(faces) > 0 and self.is_processing:
self.VideoView.setStyleSheet("background-color: rgb(0, 255, 204)")
for (x, y, w, h) in faces:
cv2.rectangle(frame, (x, y), (x + w, y + h), (255, 255, 0), 2)
else:
self.set_UserName([False, "欢迎光临"])
self.VideoView.setStyleSheet("background-color: rgb(102, 204, 255)")
self.frame_count += 1
if self.frame_count > 30:
end_time = time.time()
elapsed_time = end_time - self.start_time
fps = self.frame_count / elapsed_time
integer_fps = int(fps)
self.FPSLabel.setText(f"FPS: {integer_fps}")
self.start_time = time.time()
self.frame_count = 0
h, w, ch = frame.shape
bytes_per_line = ch * w
convert_to_qt_format = QImage(frame.data, w, h, bytes_per_line, QImage.Format_RGB888)
pixmap = QPixmap.fromImage(convert_to_qt_format)
self.VideoLabel.setPixmap(pixmap.scaled(self.VideoLabel.size(), Qt.KeepAspectRatio, Qt.SmoothTransformation))
def closeEvent(self, event):
if hasattr(self, 'image_thread') and self.image_thread.isRunning():
self.image_thread.finished.disconnect()
self.image_thread.quit()
self.image_thread.wait()
if self.cap is not None and self.cap.isOpened():
self.cap.release()
super(MainWindow, self).closeEvent(event)
if __name__ == '__main__':
app = QApplication(sys.argv)
window = MainWindow()
sys.exit(app.exec_())

 电子发烧友论坛
电子发烧友论坛
 /6
/6 



 工商网监
湘ICP备2023018690号
工商网监
湘ICP备2023018690号




 1150
1150














 淘帖
淘帖 显身卡
显身卡




