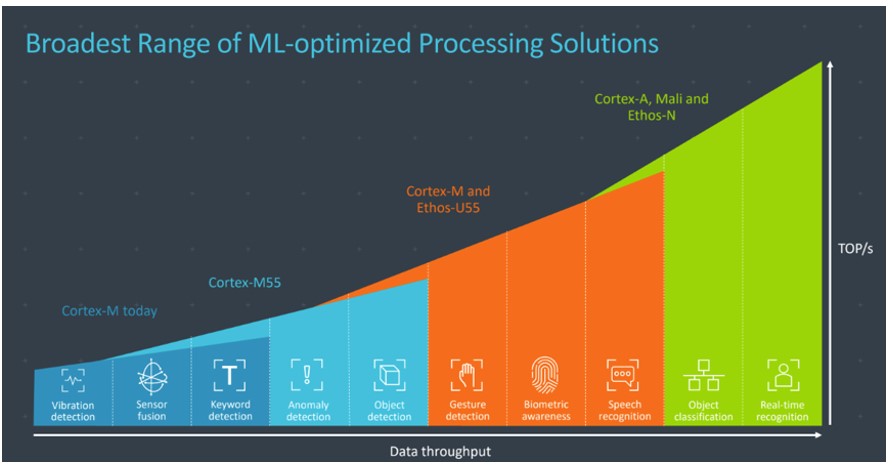
Cortex-M55 处理器是 Arm 最具 AI 能力的 Cortex-M 处理器,也是第一款基于 Arm Helium 技术的 CPU。 虽然 Cortex-M55 的速度足以在微型微控制器上运行 ML 模型,但与 Arm Ethos-U55 microNPU 的集成可以将嵌入式系统中的 ML 推理速度提高 480 倍。
Ethos-U55 是一种机器学习处理器,经过优化可以执行常见的数学 ML 算法操作,例如卷积或激活函数。Ethos-U 处理器支持流行的神经网络模型,例如用于音频处理、语音识别、图像分类和对象检测的 CNN 和 RNN。
在 Ethos-U NPU 上部署推理
要在 Ethos-U NPU 上运行推理,必须将网络运营商量化为 8 位(无符号或有符号)或 16 位(有符号),因为 Ethos-U 仅支持 8 位权重或 16 位激活. TensorFlow 模型优化工具包使开发人员能够优化 ML 模型,以便在内存、功率限制和存储限制的设备上进行部署。有不同的优化技术,包括量化、修剪和聚类, 它们是 TensorFlow 模型优化工具包的一部分,并且与 TensorFlow Lite 兼容。例如,您可以执行训练后整数量化 在使用 TFLiteConverter 加载转换后的模型后,将权重和激活从浮点数转换为整数。 请注意,一旦对模型进行了修剪和聚类,通常会在修剪/聚类后进行一次小型训练,以解决准确性损失的问题。因此,您需要在模型复杂性和大小之间进行权衡。
使用训练后量化优化您的模型:
def representative_dataset():
for _ in range(100):
# Using some random data for testing purposes
data = np.random.rand(1, 244, 244, 3)
yield [data.astype(np.float32)]
Load the model into TensorFlow using TFLite converter
converter = tf.lite.TFLiteConverter.from_saved_model(“model_tf”)
Set options for full integer post-training quantization
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.representative_dataset = representative_data_gen
Ensure that if any ops can't be quantized, the converter throws an error
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
Set the input and output tensors to int8
converter.inference_input_type = tf.int8
converter.inference_output_type = tf.int8
Convert to TFLite
tflite_model_quant = converter.convert()
要在 Ethos-U 上部署您的NN模型,您需要使用Vela编译经过训练的量化模型, 以便为 Ethos-U 生成优化的 NN 模型。Vela 是一个开源 Python 工具,可将 TFLite NN 模型编译为可在包含 Arm Ethos-U NPU 的嵌入式系统上运行的优化版本。您可以通过运行 $pip install ethos -u- vela 命令安装 Vela,然后使用特定的 Ethos-U NPU配置(例如 ethos - u55-128 )编译网络 运行以下命令行。

Accelerator-config 指定要在以下之间使用的 microNPU 配置:
精神-u55-256
精神-u55-128
精神-u55-64
精神-u55-32
精神-u65-256
精神-u65-512

图 1:Vela 工作流程
Vela 的输出是一个优化的 TensorFlow Lite 文件,可以在使用 Ethos-U NPU 的系统上进行部署,在本例中是配置了 Corstone-300 FVP 的 Arm 虚拟硬件。
通常,您可以使用TensorFlow Lite Interpreter Python API从磁盘加载 TFLite 模型进行部署。

然而,大多数微控制器没有文件系统,因此需要额外的代码和空间来从磁盘加载模型。一种有效的方法是在 C 源文件中提供模型,该文件可以包含在我们的二进制文件中并直接加载到内存中。为此,您需要使用适用于微控制器的 TensorFlow Lite C++ 库来加载模型并进行预测。 另一种快速简便的方法是使用开源Arm ML 嵌入式评估套件。它使开发人员能够使用面向 Arm Cortex-M 55和 Ethos-U微控制器的微控制器推理引擎使用 TensorFlow Lite 快速执行神经网络模型 。
E估值K it概述
Arm ML 评估 套件 允许 开发人员快速构建和部署用于 Arm Cortex-M55 和 Arm Ethos-U55 NPU 的嵌入式 机器 学习 应用程序。 它包含为 Ethos-U55 系统开发的软件 ML 应用程序,包括:
图像分类,
关键字发现(KWS),
自动语音识别 (ASR)
异常检测
人员检测
因此,您可以使用这些即用型 ML 示例快速评估在 Cortex-M CPU 和 Ethos-U NPU 上运行的网络的性能指标。您还可以使用评估套件中提供的通用推理运行器轻松为 Ethos-U 创建自定义 ML 软件应用程序。通用推理运行器允许您输入任何模型并获得性能矩阵,例如 NPU 周期数和跨不同总线的内存事务量。
ML Embedded 评估套件软件和硬件堆栈
评估套件的软件堆栈包含不同的层,顶部是应用程序,底部是依赖项。在为 Ethos-U NPU配置构建系统 后,集成 TensorFlow Lite for Microcontrollers 与 Ethos-U NPU 驱动程序执行某些可由 Ethos-U NPU 加速的算子。对于 NPU 上不受支持的神经网络模型算子,推理使用 CMSIS-NN 在 CPU 上运行。CMSIS-NN 优化 CPU 工作负载执行或使用推理引擎提供的参考内核。硬件抽象层 (HAL) 源提供了与平台无关的 API 来访问特定于硬件平台的功能。
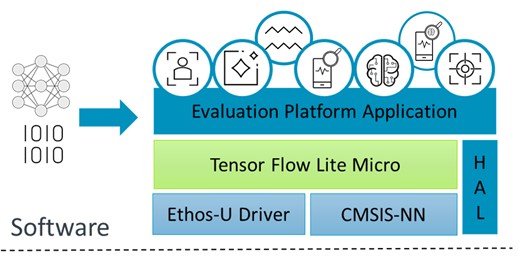
图 2:ML 评估套件软件堆栈
ML 评估套件基于 Arm Corstone-300 参考包,可帮助 SoC 设计人员更快地构建安全系统。它利用 Arm Cortex-M55处理器最大限度地提高物联网和嵌入式设备的性能。 Corstone-300 可以轻松集成 Ethos-U55,该平台可用作生态系统 FPGA (MPS3) 和固定虚拟平台 (FVP),以允许在硬件可用之前进行开发(硅硬件即将发布)。

图 3:ML 评估套件硬件堆栈
带有 Ethos-U55 和 Arm 虚拟硬件的Corstone-300 FVP

ML 评估套件工作流程
构建和运行准备使用 ML Eval Kit ML 示例的常见工作流程,例如使用 ML-Eval-Kit 在 Cortex-M 和 Ethos-U 上进行关键字定位,如下所示:
1 确保已安装以下先决条件并且它们在路径上可用。

2 克隆 Ethos-U 评估套件存储库

3 拉取所有外部依赖项
$ git submodule update --in it
4 执行build_default.py以使用默认设置(如 MPS3 FVP目标和 Ethos-U55 时序适配器) 配置构建系统。
$ python build_default。
$ python build_default。
5 使用 make 命令编译项目
6 构建的结果放在 build/bin 目录下,例如:
垃圾桶
├── ethos-u-<use_case_name>.axf
├── ethos-u-<use_case_name>.htm
├── ethos-u-<use_case_name>.map
└── 行业
├── 音频.txt
└── <用例>
├── ddr.bin
└── itcm.bin
7 如果使用 FVP ,则在带有 Arm 虚拟硬件的 FVP 上启动所需的应用程序。 例如,Ethos-U55 上的关键字识别用例可以通过以下命令启动:
$ FVP_Corstone_SSE-300_Ethos-U55 -一个。/构建/ bin / ethos-u-kws。轴心
使用 ML Embedded Evaluation Kit 配置和运行自定义模型
ML Eval Kit 也非常易于与自定义工作流程和 NN 模型一起使用。例如,您可以将新模型而不是 MobileNet 与输入大小一起传递给图像分类。 但是,要在Ethos-U NPU 上运行您的特定 ML模型,请确保您的自定义模型已成功通过V ela 编译器运行以生成优化的 NN 模型。然后通过创建构建目录并设置 Vela 生成的 TFLite 文件的路径,使用 Cmake 配置构建系统。最后,使用 make 编译项目。
您可以使用Generic Inference Runner ML Eval Kit 构建选项来分析您在Cortex-M55 和 Ethos-U55上的特定 ML 应用程序的推理速度。这些可以通过运行以下命令来完成:
$ mkdir 构建 && cd 构建
$ cmake .. \
- Dinference_runner_MODEL_TFLITE_PATH = TFLITE_PATH
- DUSE_CASE_BUILD = inference_runner
有关可与 cmake 一起使用的不同参数选项的更多信息, 请参阅构建默认配置。
$制作
然后使用 Arm 虚拟硬件选择 Ethos-U55 在 FVP 上运行应用程序二进制文件。
注意:Arm 虚拟硬件 FVP 执行上的 MAC 数量应与 Vela 编译器--accelerator-config配置上的相同。
FVP_Corstone_SSE-300_Ethos-U55 - C ethosu。num_macs = 128 -一个。/ build / bin / ethos-u-inference_runner。轴心
今天试试
您现在可以使用 ML 评估套件、Arm 虚拟硬件中提供的 Corstone-300 FVP、Arm Vela 编译器和可用的 ML 示例开始为 Arm Ethos-U NPU 开发 ML 软件。
原作者:埃勒姆·哈里普什

 /6
/6 



 工商网监
湘ICP备2023018690号
工商网监
湘ICP备2023018690号






 2099
2099








 淘帖
淘帖



